By Saurabh Vakil and Jim Davis
A team of researchers from Stanford University created a personal health management tool that combines electronic record (EHR) data with machine learning to accurately diagnose patients with abdominal aortic aneurysm, also called AAA.
The problem for doctors is that this cardiovascular disease is asymptomatic as it grows. As a result, healthcare providers often diagnose the condition at a late stage. A report recently published in Cell describes how researchers integrated genome and EHR data into a new machine learning framework to predict patient diagnoses of the heart condition. Researchers attempted to use this framework to diagnose the condition earlier for more timely treatment.
If the futurists, visionaries, and venture capitalists are to be believed, this example of applied artificial intelligence is right on the cusp of becoming the most important breakthrough for healthcare, since penicillin.
At the high powered conference on “Harnessing Artificial Intelligence and Machine Learning to Advance Biomedical Research” hosted by National Institutes of Health (NIH) in July 2018, a number of exciting opportunities that hold a great promise for the future of healthcare were highlighted.
Dr. Francis Collins, director of the NIH, was explicit about the institute’s commitment to embrace the formidable agenda, both in terms of the opportunities for research and the challenges which they will inevitably entail. He highlighted the significance of data by referring to it as the fodder for machine learning and AI. The workshop participants parted with an unmistakable appreciation of big data management as one of the thorniest challenges in need of urgent mitigation for AI/ML/Big Data research to make meaningful progress.
Do researchers in AI for healthcare have enough data to work with? In order to prioritize and harmonize large data sets, first, you need availability and access to large data sets.
The Data Sharing Challenge
One of the primary requirements in AI is the availability of data in large quantities. Machines are “trained” to acquire artificial intelligence using Big Data. Dr. David Heckerman, Distinguished Scientist for Amazon and Chief Data Scientist for Human Longevity said at the same workshop that data availability is taken for granted. Heckerman warned that more needs to be done to motivate all stakeholders, including doctors in private practice, researchers, institutions to share data without hesitation.
Two main reasons are accorded to this hesitation. One is due to the doctors in private practice equating data with dollars. Two, and probably more significant are the data privacy and protection concerns. While dealing with the doctors’ individual motivational issues falls in the realm of behavioral science and a mental paradigm shift, the ones related to data protection can be expected to be addressed using more tangible solutions.
Fear of the Data Breach
Big data is currently one of the most critical emerging technologies. The 4V’s of big data – volume, velocity, variety, and veracity-makes the data management and analytics challenging for the traditional data warehouses.
Big data, analytics, and cloud computing are generally referenced together to highlight a unified computing paradigm. However, working on Big Data in the cloud brings its own challenges; notably that of privacy and protection.
In today’s environment of an onslaught of news about data breaches, it can be tough for a CIO to sell a strategy involving a transition to the cloud to the top management of his/her healthcare organization without informed justification.
And for good reason: the cost of a data breach for healthcare organizations continues to rise, from $380 per record last year to about $408 per record this year, as the healthcare industry also continues to incur the highest cost for data breaches compared to any other industry, according to a new study from IBM Security and the Ponemon Institute.
For the eighth year in a row, healthcare organizations had the highest costs associated with data breaches-nearly three times higher than the cross-industry average ($148), according to the study. The next highest industry was financial services with an average of $206 per lost or stolen record. Multiply the average cost with the number of records breached every year (that run into the millions), and the total cost can be staggering. However, in today’s hyper-competitive environment, the financial pressure to transition to cloud services is helping to overcome the industry’s typical caution.
For their part, healthcare investors realize that most ERP’s will not be supported outside the cloud environment some 2 to 5 years down the road. That’s because there’s a more compelling financial upside in the ability to derive value from patient data to improve outcomes, and that doing so requires technology that facilitates the free flow of information.
With cloud technology, a more holistic view of a patient can be securely transmitted between hospitals, specialties and other healthcare institutions. As a matter of fact, users stand to improve their security profile on the cloud as cloud vendors have more robust cybersecurity than hospitals can ever build by themselves.
The Role of Encryption in Data Protection
Data in Transit/Data at Rest: With growing adoption of cloud services, you might expect constant mobilization of a large amount of data over the internet between corporate networks and cloud infrastructure. Since data is exposed to risks both in transit and at rest, it requires protection in both states. Consequently, encryption plays a major role in data protection. For data in transit, enterprises often choose to encrypt sensitive data prior to moving and/or use encrypted connections (HTTPS, SSL, TLS, FTPS, etc.) to protect the contents of data in transit. For data at rest, enterprises can simply encrypt sensitive files prior to storing them and/or choose to encrypt the storage drive itself.
So, data in transit and data at rest have reasonably good protection. This has helped in alleviating fear among healthcare companies and fueled the transition to cloud to a good extent.
Still, that’s not good enough protection.
Enterprises in healthcare and other industries (as well as investors) have been waiting for the data in its third and more fluid state, in use, to be adequately protected. Hackers are always hiding in the dark alleys poking around for vulnerabilities and ready to pounce on this vulnerable prey. Protecting data by enabling better control over access to applications and data has been a focus of considerable development and investment activity, but hackers have still been making merry while valuable data is breached, and millions of dollars are lost because they know that data is in the clear when it is being processed. And not all losses are due to hacking by outsiders – insiders, either by design or accident, are also responsible for a large number of unauthorized access or disclosure of healthcare information.
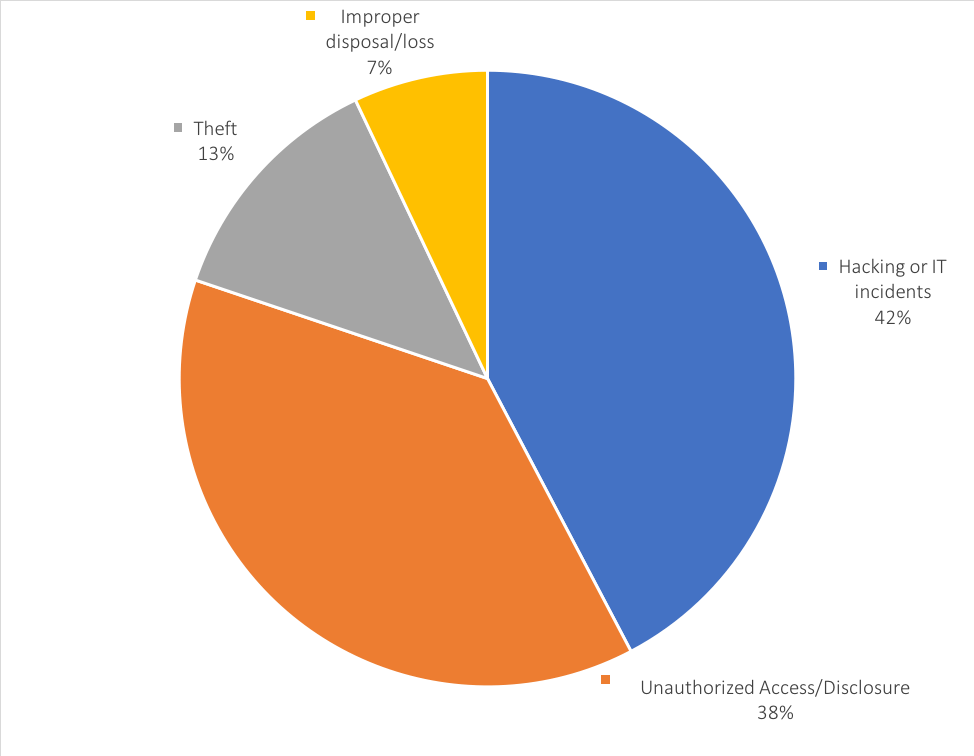
The U.S. Department of Health and Human Services (Office for Civil Rights) maintains records of “breaches of unsecured protected health information affecting 500 or more individuals.” According to OCR records, there are 227 incidents that have been reported in 2018 and are currently under investigation. Of these, 96 are classified as “hacking or IT incidents”, 29 are classified as theft, and 86 are incidents of unauthorized access or disclosure.
What the “hack” is happening with “Data in Use”?
Recent chip flaw disclosures by Intel and others rattled the industry and the assumptions they held about protections computers provide while it resides in system memory. The flaws expose an attack surface that is often overlooked: the processing layer.
In the conventional processing schemes, data must be decrypted before being worked on. This is the “data in use” vulnerability everyone is talking about.
The problem lies in the way most modern processors have been built to rely on speculative execution, a technique which helps them optimize performance. Essentially what the processors do is try to predict the instructions they are going to be asked to carry out next without adequate authorization to access that data. They then queue up and execute the necessary next bit of code so they are ahead of the game. There are times when they guess wrong, however.
In these cases, they undo the speculative code, but they do not completely roll back every step they have taken. As a result, remnants of data they were not actually meant to fetch are left in cache memory. This is one of the major scenarios in which the “data in use” vulnerability originates.
Can data remain encrypted while in use?
Baffle, a Silicon Valley tech startup, is one of a small handful of companies working on securing data in use. Baffle has built an advanced data protection solution around the concept of Secure Multi-Party Compute (SMPC), which enables users to perform operations on encrypted data without ever needing to first decrypt the data. Using industry-standard AES encryption and customer-owned keys, Baffle’s Advanced Data Protection solution never exposes sensitive information. This means that data in use, in memory, in the search index, and data at rest is always protected. While the concept of homomorphic encryption has been around for decades, it has been impractical to implement because of the additional computational requirements and a significant performance degradation. Baffle, however, says it has overcome these challenges to offer a solution that doesn’t impact application performance and, moreover, doesn’t require developers to rewrite the application.
Indeed, Baffle claims to be the first company to guarantee data protection by enabling a commercial application to query encrypted data in a commercial database such as MySQL, Microsoft SQL Server, Oracle, Postgres as well as Cassandra or MongoDB. At its core, the Baffle solution consists of three components; BaffleShield-a reverse-proxy at the SQL layer beneath the JDBC/ODBC driver, Baffle Secure Servlets – a cluster of stateless compute engines and BaffleManager-a management console. Together these components accept encrypted data using customer-owned keys, performs requested operations and returns the data in encrypted form before revealing the results in the clear in the application. Baffle says the solution will facilitate acceleration of cloud migration, big data analytics, and data sharing initiatives.
In addition, Baffle has developed an encryption solution for SQL and NoSQL databases that integrates seamlessly into the cloud migration process so that no unencrypted data leaves the enterprise. Baffle’s solution allows existing applications such as business intelligence and analytics applications to access and process the AES encrypted data without decrypting it, effectively mitigating the risk of data exposure in the clear at any time in the cloud environment.
Keys used to encrypt and decrypt the data with AES encryption are always in the customer’s control. Baffle supports both AWS RDS and Azure as well as hybrid and private cloud environments.
The ability to support data migration makes Baffle very relevant to the healthcare industry, but there’s another key role that its Advanced Data Protection solution can play in the industry-securing patient health records. In a briefing with Edge Research Group, Ameesh Divatia, Baffle’s CEO, emphasized the special significance of the solution for healthcare companies who must have patient data encrypted in the cloud by law in view of HIPAA compliance. Divatia, a serial entrepreneur who has previously steered three startups in the datacenter infrastructure market to acquisitions, related his account of how Baffle is addressing the healthcare challenge.
While Baffle’s technology is designed to work and support cloud migration initiative of any vertical, healthcare figures prominently in the discussion of the company’s business initiatives.
The recent major data breaches among healthcare companies such as Banner Health, Newkirk Products, 21st Century Oncology, Valley Anesthesiology Consultants, County of Los Angeles Dept. of Health and Mental Health, and many more have motivated Baffle to focus on the sensitivity of e-PHI data and the pressing need to protect it.
Baffle’s software-based solution identifies e-PHI data and identifies where it is stored and processed across on-premise and cloud-based databases. This process ensures that you can identify and encrypt all of a provider’s e-PHI data. The centralized BaffleShield solution ensures that the identified e-PHI data is encrypted for all applications and all databases and that the customer is audit ready at all times. There are also elements of the Baffle solution that could help customers avoid the requirement for data breach notification when data is lost since any records that are lost are encrypted and hence exempt from the notification requirement.
Baffle has recently reached a major milestone. The United States Patent and Trademark Office awarded the company a patent for its approach to processing data on “untrusted” computers. The announcement comes on the heels of releasing a solution for enabling the holy grail of encryption – secure mathematical computation and wildcard search on AES encrypted data in use and in memory with any application, whether it is custom, hosted or Software as a Service (SaaS).
Conclusion
It may still take a few years before clinicians can sit back and relax while their robot assistants take a crack at diagnosing their patients, but the development of artificial intelligence and machine learning is moving quickly.
Healthcare organizations recognize the significance of having access to free-flowing data across disparate systems and migration to the cloud as the only means to achieve this objective.
Patient privacy, safety and data security are pressing near-term issues for AI in healthcare.
The National Institute of Health (NIH) and the government are already thinking about how to address issues of safety, regulation, fairness and security as AI systems move from laboratories to real-world settings.
“The first order of business for NIH would be to prioritize data sets of greatest interest and harmonize them to make them machine learnable. Everyone loves to hate EHR but care would have to be taken to safeguard its significance and use” observed Collins, the NIH director.
According to a 2016 report from the National Science and Technology Council (NSTC), “The best way to build capacity for addressing the longer-term speculative risks is to attack the less extreme risks already seen today, such as current security, privacy, and safety risks, while investing in research on longer-term capabilities and how their challenges might be managed,” the White House suggests, reinforcing the idea that addressing issues of data protection and patient privacy as soon as possible will prepare healthcare for an AI-driven future.
With comprehensive data protection at their disposal, such as the kind that Baffle has proposed, healthcare organizations are in a better position than ever before to embrace data sharing and cloud computing.
